Research
Research Publication Summary
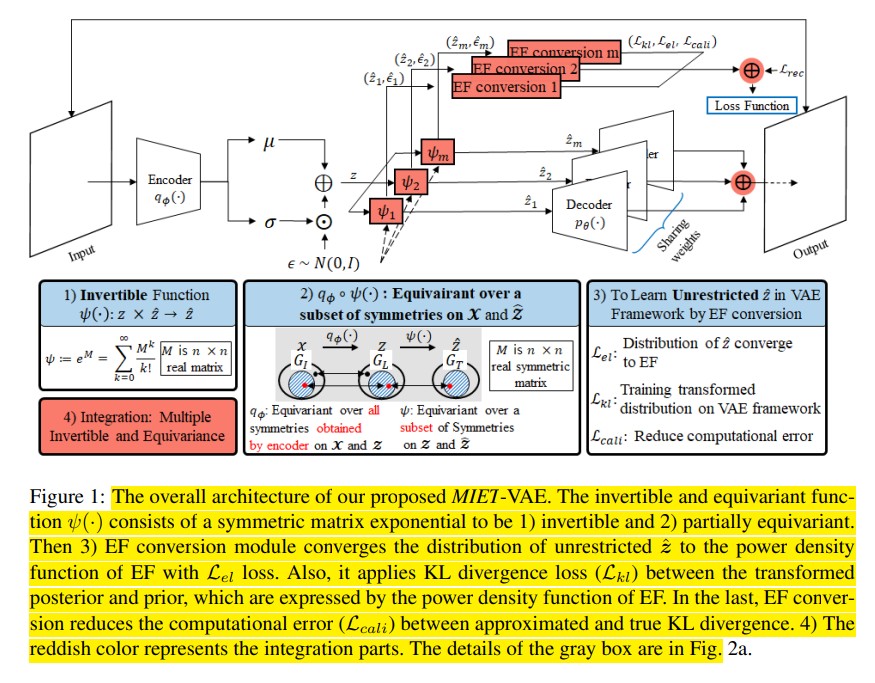
Multiple Invertible and Equivariant Transformation for Disentanglement in VAEs
The 29th International Conference on Artificial Intelligence and Statistics (AISTATS 2026)
-
Abstract
Disentanglement learning is a core issue for understanding and re-using trained information in Variational AutoEncoder (VAE), and effective inductive bias has been reported as a key factor. However, the actual implementation of such bias is still vague. We propose Multiple Invertible and Equivariant transformation (MIE-transformation), which injects inductive bias by: 1) guaranteeing invertibility of latent-to-latent transformation while preserving equivariance of input-to-latent transformation via symmetric matrix exponential (IE-transformation), 2) extending prior and posterior to unrestricted forms through learnable conversion to an approximated exponential family (EF-conversion), and 3) integrating multiple units of IE-transformation and EF-conversion. MIE-transformation can be simply inserted into existing VAEs and improves disentanglement performance across various benchmarks.
- Question: How can we inject effective inductive bias for unsupervised disentanglement learning in VAEs, given that prior methods lack clear implementation of such bias and unrestricted latent transformations break equivariance?
- Idea: Use symmetric matrix exponential (e^S where S is symmetric) as the latent-to-latent transformation function. This guarantees invertibility while preserving equivariance over a subset of symmetries (Proposition 1-3). EF-conversion then enables training with arbitrary latent distributions by approximating them as exponential family.
- Dataset: dSprites, 3D Shapes, 3D Cars
- Method: MIE-transformation (Symmetric Matrix Exponential IE-transformation + Exponential Family Conversion + Multiple Unit Integration)
- Keywords: Disentanglement, Variational AutoEncoder, Equivariance, Invertibility, Matrix Exponential, Exponential Family, Inductive Bias
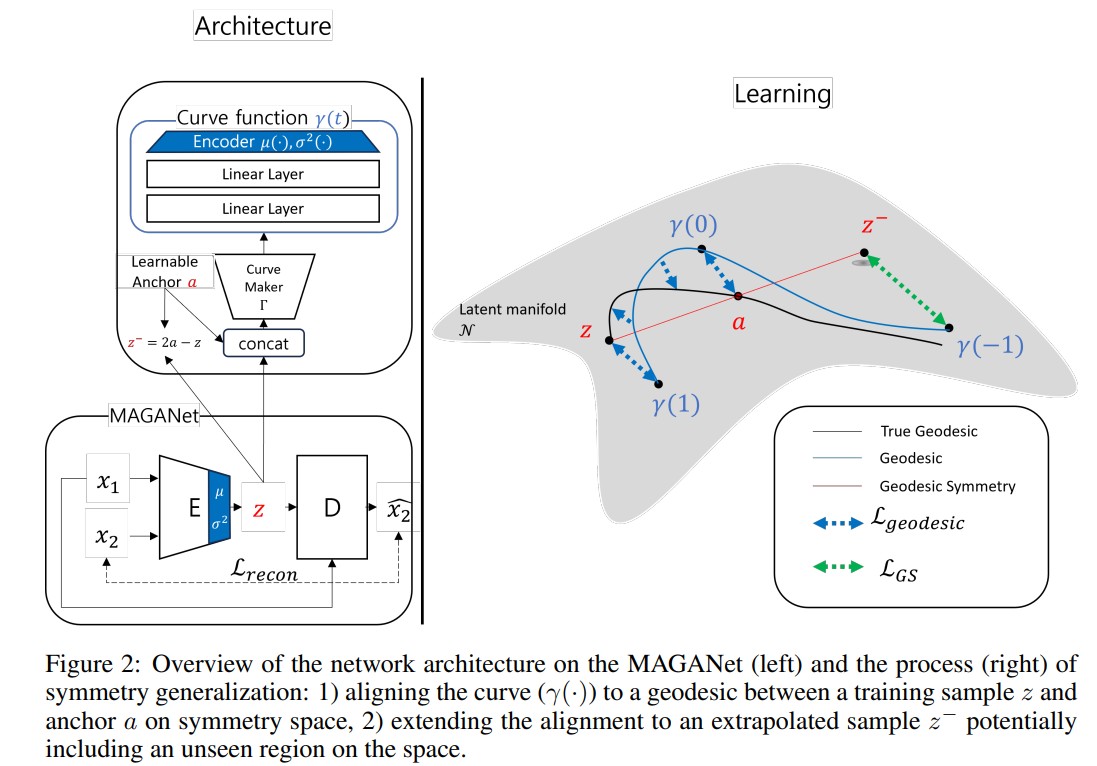
Symmetric Space Learning for Combinatorial Generalization
The 2026 International Conference on Learning Representations (ICLR 2026)
-
Abstract
Combinatorial generalization (CG)—generalizing to unseen combinations of known semantic factors—remains a fundamental challenge in machine learning. While symmetry-based methods are promising, they learn from observed data and thus fail at what we term symmetry generalization: extending learned symmetries to novel data. We address this by proposing a novel framework that endows the latent space with the structure of a symmetric space. This class of manifolds provides a principled geometric foundation for extending learned symmetries. Our method operates in two steps: first, it imposes this structure by learning the underlying algebraic properties via the Cartan decomposition of a learnable Lie algebra. Second, it uses geodesic symmetry as a powerful self-supervisory signal to ensure this learned structure extrapolates from observed samples to unseen ones. A detailed analysis on a synthetic dataset validates our geometric claims, and experiments on standard CG benchmarks show our method significantly outperforms existing approaches.
- Question: How can we extend learned symmetries beyond observed training data to achieve combinatorial generalization? Existing symmetry-based methods are confined to the training distribution and cannot generalize to unseen factor combinations.
- Idea: Impose symmetric space structure on the latent manifold. The Cartan Loss enforces valid algebraic structure via Lie bracket relations, while the Geodesic Symmetry Consistency (GSC) Loss leverages the geometric property that geodesic symmetry corresponds to negation in tangent space, enabling extrapolation to unseen regions.
- Dataset: dSprites, 3D Shapes, MPI3D, 3D Sphere
- Method: CartanFM (Cartan Loss + Geodesic Symmetry Consistency Loss + Conditional Flow Matching)
- Keywords: Combinatorial Generalization, Symmetric Space, Lie Algebra, Cartan Decomposition, Geodesic Symmetry, Flow Matching
Preference Distillation via Value based Reinforcement Learning
The 39th Conference on Neural Information Processing Systems (NeurIPS 2025)

-
Abstract
Direct Preference Optimization (DPO) is a powerful paradigm to align language models with human preferences using pairwise comparisons. However, its binary win-or-loss supervision often proves insufficient for training small models with limited capacity. Prior works attempt to distill information from large teacher models using behavior cloning or KL divergence. These methods often focus on mimicking current behavior and overlook distilling reward modeling. To address this issue, we propose Teacher Value-based Knowledge Distillation (TVKD), which introduces an auxiliary reward from the value function of the teacher model to provide a soft guide. This auxiliary reward is formulated to satisfy potential-based reward shaping, ensuring that the global reward structure and optimal policy of DPO are preserved. TVKD can be integrated into the standard DPO training framework and does not require additional rollouts.
- Question: How can we effectively distill preference alignment from large teacher models to small student models, given that DPO's binary supervision is too coarse and prior KD methods focus on behavior imitation rather than reward modeling?
- Idea: Use the teacher's value function as auxiliary reward via potential-based reward shaping (PBRS). The shaping term ψ(s,a) = V_φ(s') - V_φ(s) provides soft sequence-level guidance while theoretically preserving the optimal policy, unlike action-dependent terms (e.g., log π or Q) which violate policy invariance.
- Dataset: DPO-MIX-7K, HelpSteer2
- Method: TVKD (Teacher Value-based Knowledge Distillation with PBRS-compliant auxiliary reward integrated into DPO loss)
- Keywords: Preference Distillation, Direct Preference Optimization, Value Function, Potential-based Reward Shaping, Knowledge Distillation, Small Language Models
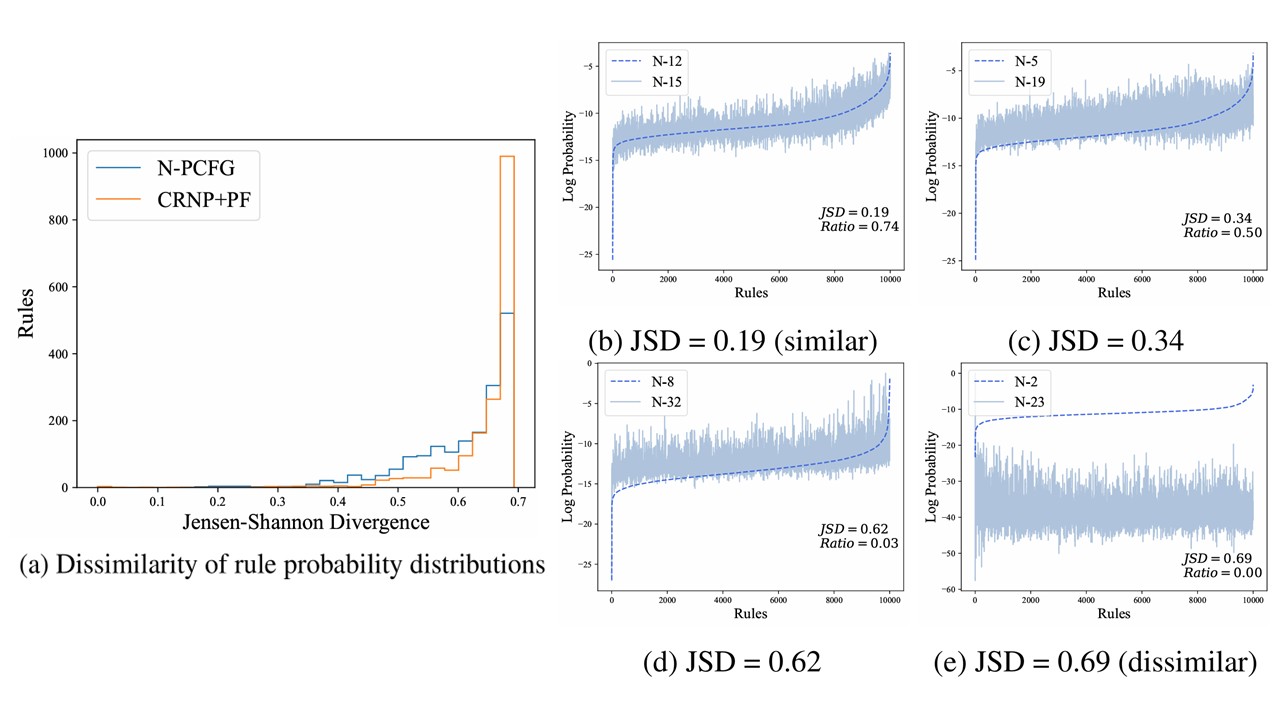
Probability Distribution Collapse: A Critical Bottleneck to Compact Unsupervised Neural Grammar Induction
The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025) Main
-
Abstract
Unsupervised neural grammar induction aims to learn interpretable hierarchical structures from language data. However, existing models face an expressiveness bottleneck, often resulting in unnecessarily large yet underperforming grammars. We identify a core issue, **probability distribution collapse**, as the underlying cause of this limitation. We analyze when and how the collapse emerges across key components of neural parameterization and introduce a targeted solution, **collapse-relaxing neural parameterization**, to mitigate it. Our approach substantially improves parsing performance while enabling the use of significantly more compact grammars across a wide range of languages, as demonstrated through extensive empirical analysis.
- Question: Are current neural grammars truly utilizing their capacity? How can we enable them to learn more compact and effective grammars by utilizing whole capacity?
- Idea: Probability distribution collapse hinder that the models utilize the whole capacity of neural model. We analyze when and how the collapse emerges and propose simple solution to relax the collapse.
- Dataset: PTB, CTB, SPMRL
- Method: Collapse-Relaxing Neural Parameterization
- Keywords: Unsupervised grammar induction, Probability Distribution Collapse
RSCF: Relation-Semantics Consistent Filter for Entity Embedding of Knowledge Graph
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025)

-
Abstract
In knowledge graph embedding, leveraging relation specific entity transformation has markedly enhanced performance. However, the consistency of embedding differences before and after transformation remains unaddressed, risking the loss of valuable inductive bias inherent in the embeddings. This inconsistency stems from two problems. First, transformation representations are specified for relations in a disconnected manner, allowing dissimilar transformations and corresponding entity embeddings for similar relations. Second, a generalized plug-in approach as a SFBR (Semantic Filter Based on Relations) disrupts this consistency through excessive concentration of entity embeddings under entity-based regularization, generating indistinguishable score distributions among relations. In this paper, we introduce a plug-in KGE method, Relation-Semantics Consistent Filter (RSCF). Its entity transformation has three features for enhancing semantic consistency: 1) shared affine transformation of relation embeddings across all relations, 2) rooted entity transformation that adds an entity embedding to its change represented by the transformed vector, and 3) normalization of the change to prevent scale reduction. To amplify the advantages of consistency that preserve semantics on embeddings, RSCF adds relation transformation and prediction modules for enhancing the semantics. In knowledge graph completion tasks with distance-based and tensor decomposition models, RSCF significantly outperforms state-of-the-art KGE methods, showing robustness across all relations and their frequencies.
- Question: How can entity transformation models learn useful inductive biases from semantically similar relations?
- Idea: Ensure that relation-specific entity transformations are more similar for semantically similar relations, and that the model learns useful semantic representations in knowledge graph embedding.
- Dataset: FB15k-237, WN18RR, YAGO3-10
- Method: Relation-Semantics Consistent Filter (RSCF)
- Keywords: Knowledge graph completion, Knowledge graph embedding
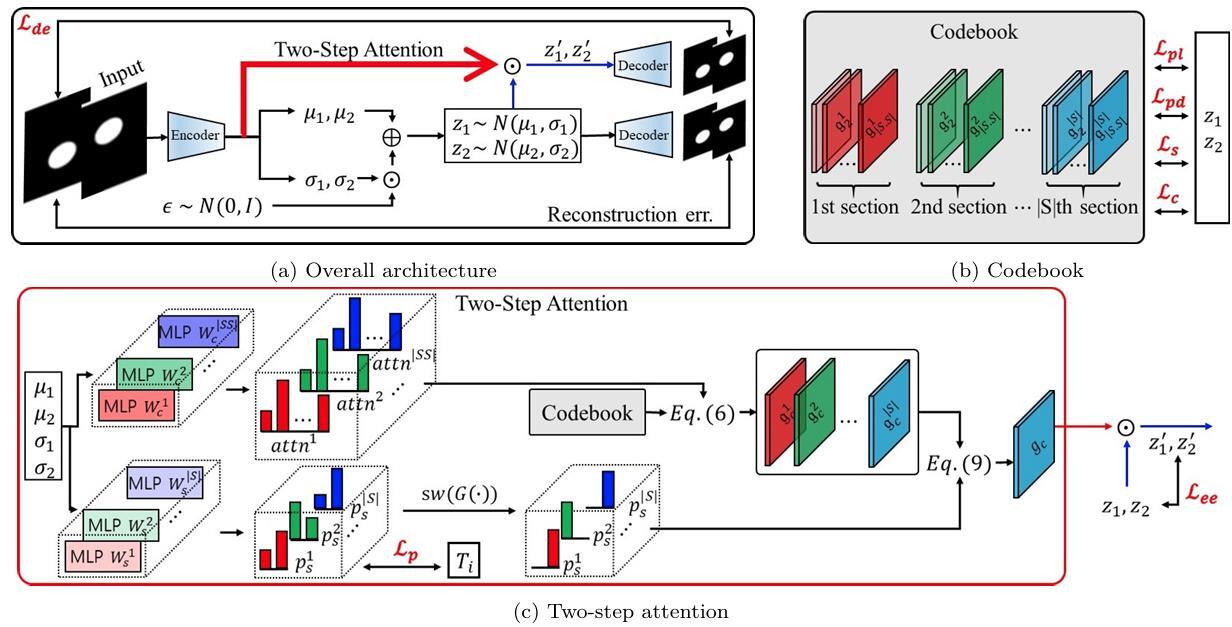
CFASL: Composite Factor-Aligned Symmetry Learning for Disentanglement in Variational AutoEncoder
Transactions on Machine Learning Research
-
Abstract
Symmetries of input and latent vectors have provided valuable insights for disentanglement learning in VAEs. However, only a few works were proposed as an unsupervised method, and even these works require known factor information in training data. We propose a novel method, Composite Factor-Aligned Symmetry Learning (CFASL), which is integrated into VAEs for learning symmetry-based disentanglement in unsupervised learning without any knowledge of the dataset factor information. CFASL incorporates three novel features for learning symmetry-based disentanglement: 1) Injecting inductive bias to align latent vector dimensions to factor-aligned symmetries within an explicit learnable symmetry code-book 2) Learning a composite symmetry to express unknown factors change between two random samples by learning factor-aligned symmetries within the codebook 3) Inducing group equivariant encoder and decoder in training VAEs with the two conditions. In addition, we propose an extended evaluation metric for multi-factor changes in comparison to disentanglement evaluation in VAEs. In quantitative and in-depth qualitative analysis, CFASL demonstrates a significant improvement of disentanglement in single-factor change, and multi-factor change conditions compared to state-of-the-art methods.
- Question: How can we perform symmetry-based disentanglement without known factor information?
- Idea: implement disentanglement learning of inductive bias vector instead of VAE
- Dataset: dSprite, CelebA, Cars3D, smallNORB
- Method: define the input and optimize the symmetry, and inject it as inductive bias
- Keywords: disentanglement learning, symmetry (group theory), variational auto-encoder.
Structural Optimization Ambiguity and Simplicity Bias in Unsupervised Neural Grammar Induction
The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024) Findings
-
Abstract
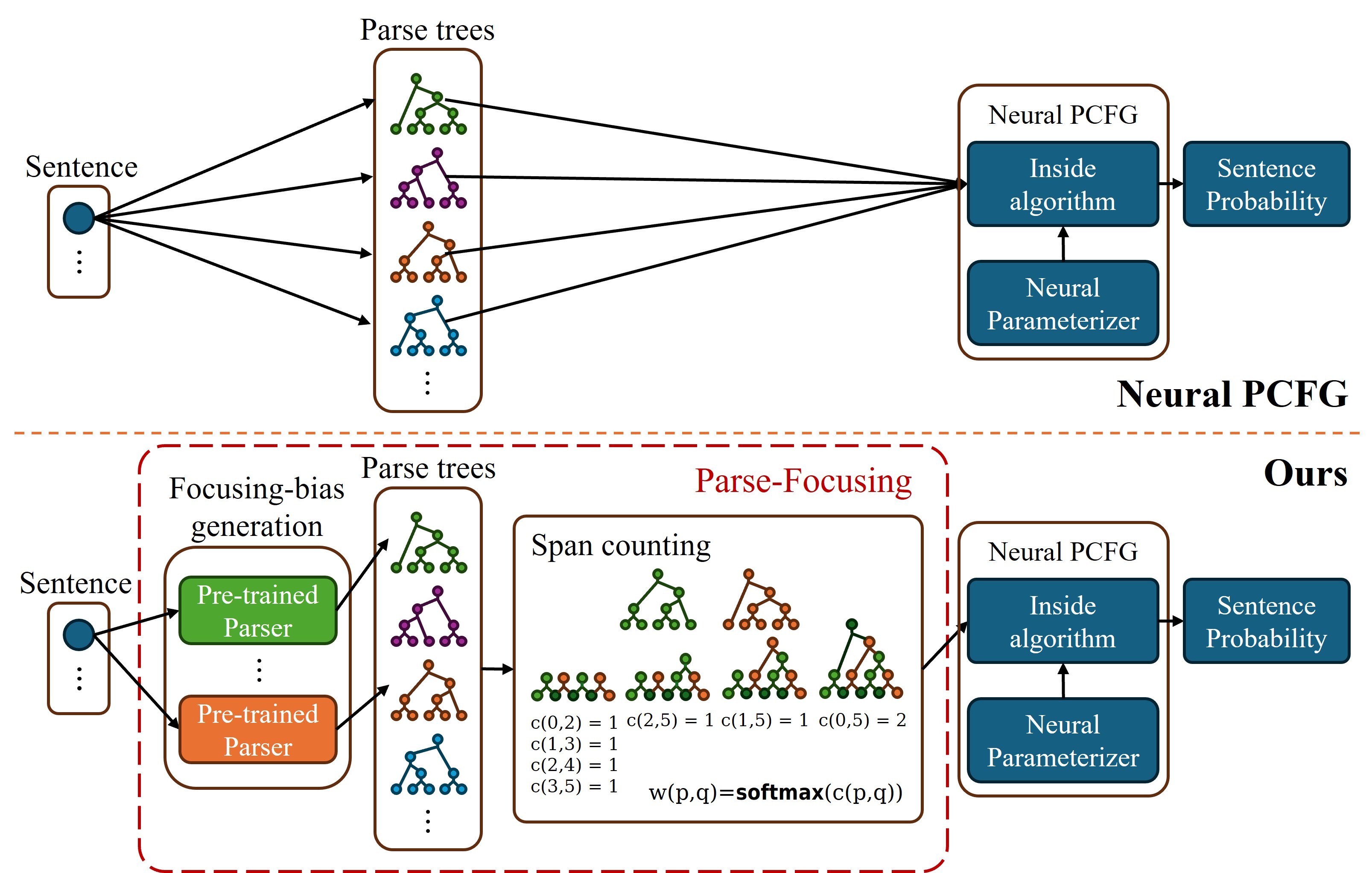
Neural parameterization has significantly advanced unsupervised grammar induction. However, training these models with a traditional likelihood loss for all possible parses exacerbates two issues: 1) **structural optimization ambiguity** that arbitrarily selects one among structurally ambiguous optimal grammars despite the specific preference of gold parses, and 2) **structural simplicity bias** that leads a model to underutilize rules to compose parse trees. These challenges subject unsupervised neural grammar induction (UNGI) to inevitable prediction errors, high variance, and the necessity for extensive grammars to achieve accurate predictions. This paper tackles these issues, offering a comprehensive analysis of their origins. As a solution, we introduce **sentence-wise parse-focusing** to reduce the parse pool per sentence for loss evaluation, using the structural bias from pre-trained parsers on the same dataset. In unsupervised parsing benchmark tests, our method significantly improves performance while effectively reducing variance and bias toward overly simplistic parses. Our research promotes learning more compact, accurate, and consistent explicit grammars, facilitating better interpretability.
- Question: Why do existing neural grammar models exhibit large variance and produce simplistic structures for some sentences? And how can we solve this?
- Idea: Use only few parse trees for given sentences
- Dataset: PTB, CTB, SPMRL
- Method: Sentence-wise Parse-Focusing and Focusing-Bias Generation
- Keywords: Unsupervised grammar induction, Unsupervised constituency parsing
Label-Focused Inductive Bias over Latent Object Features in Visual Classification
The Twelfth International Conference on Learning Representations (ICLR 2024)
-
Abstract
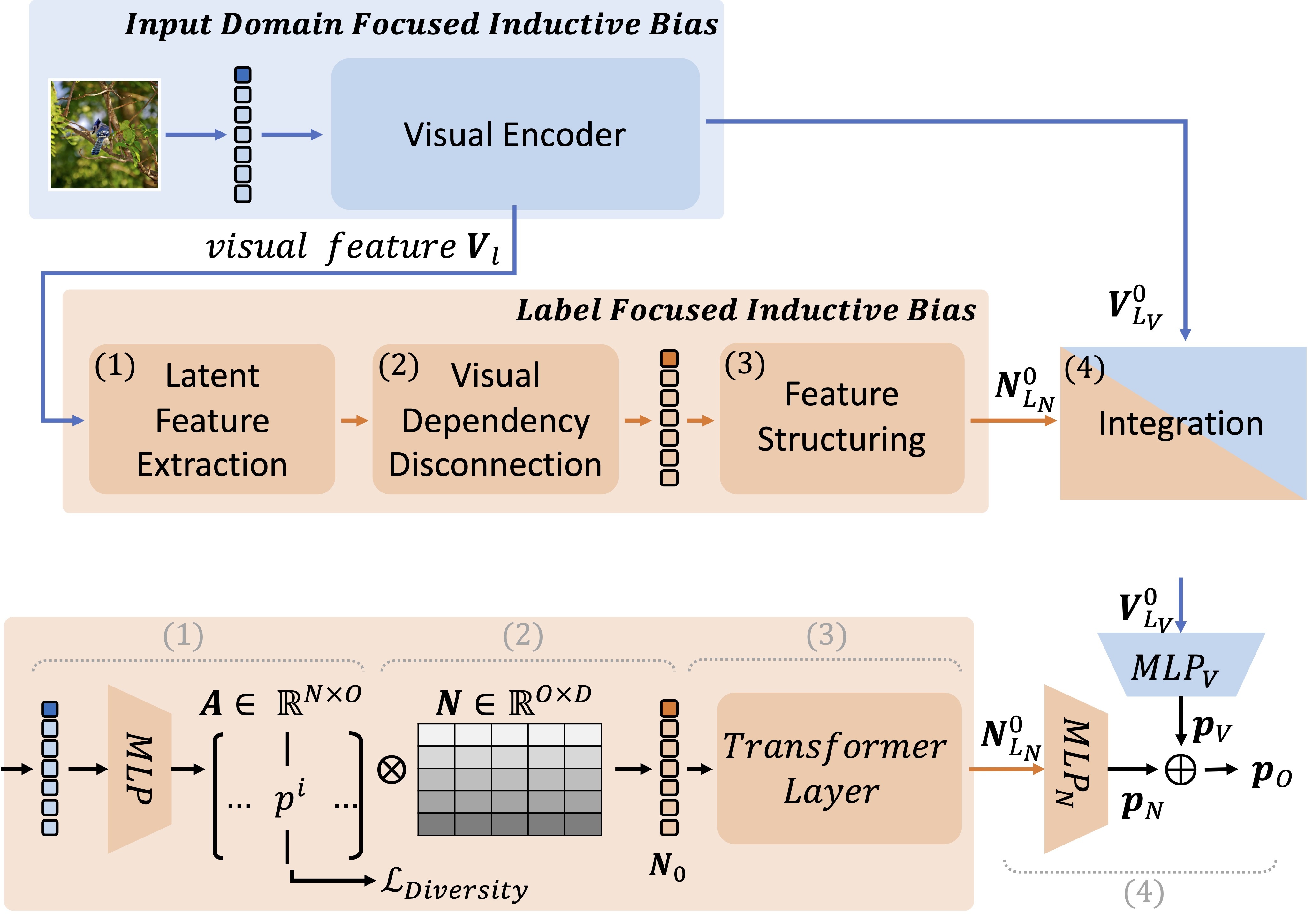
Most neural networks for classification primarily learn features differentiated by input-domain related information such as visual similarity of objects in an im- age. This input-domain focused inductive bias, while natural, can unintentionally conflict with unexpressed yet implicitly utilized relations over latent objects in human labeling, referred to Undescribed world knowledge (UWK). Such conflicts can limit generalization of models by potential dominance of the input-domain focused bias in inference. To overcome this limitation without external resources, we introduce Label-focused Latent-object Biasing (LLB) training method that con- structs label-focused inductive bias over latent objects determined by only labels as UWK. It has four steps: 1) it learns intermediate latent object features in an unsupervised manner; 2) it decouples their visual dependencies by assigning new independent embedding parameters; 3) it captures structured features optimized for the original classification task; and 4) it integrates the structured features with the original visual features for the final prediction. We implement the LLB on a vision transformer architecture, and achieved significant improvements on im- age classification benchmarks. This paper offers a straightforward and effective method to obtain and utilize undescribed world knowledge in classification tasks.
- Question: Unintentional conflicts between input image(doamin) focused inductive bias and relations over latent objects in human labeling(Undescribed world knowledge) exits, and how can we handle it?
- Idea: Constructs label-focused inductive bias over latent objects that decouples visual dependencies
- Dataset: ImageNet1K, Places356, iNaturalist2018
- Method: Label-focused Latent-object Biasing (LLB)
- Keywords: Representation Learning, Output-Domain Focused Inductive Bias, Classification
Fixed Non-negative Orthogonal Classifier: Inducing Zero-mean Neural Collapse with Feature Dimension Separation
The Twelfth International Conference on Learning Representations (ICLR 2024)
-
Abstract
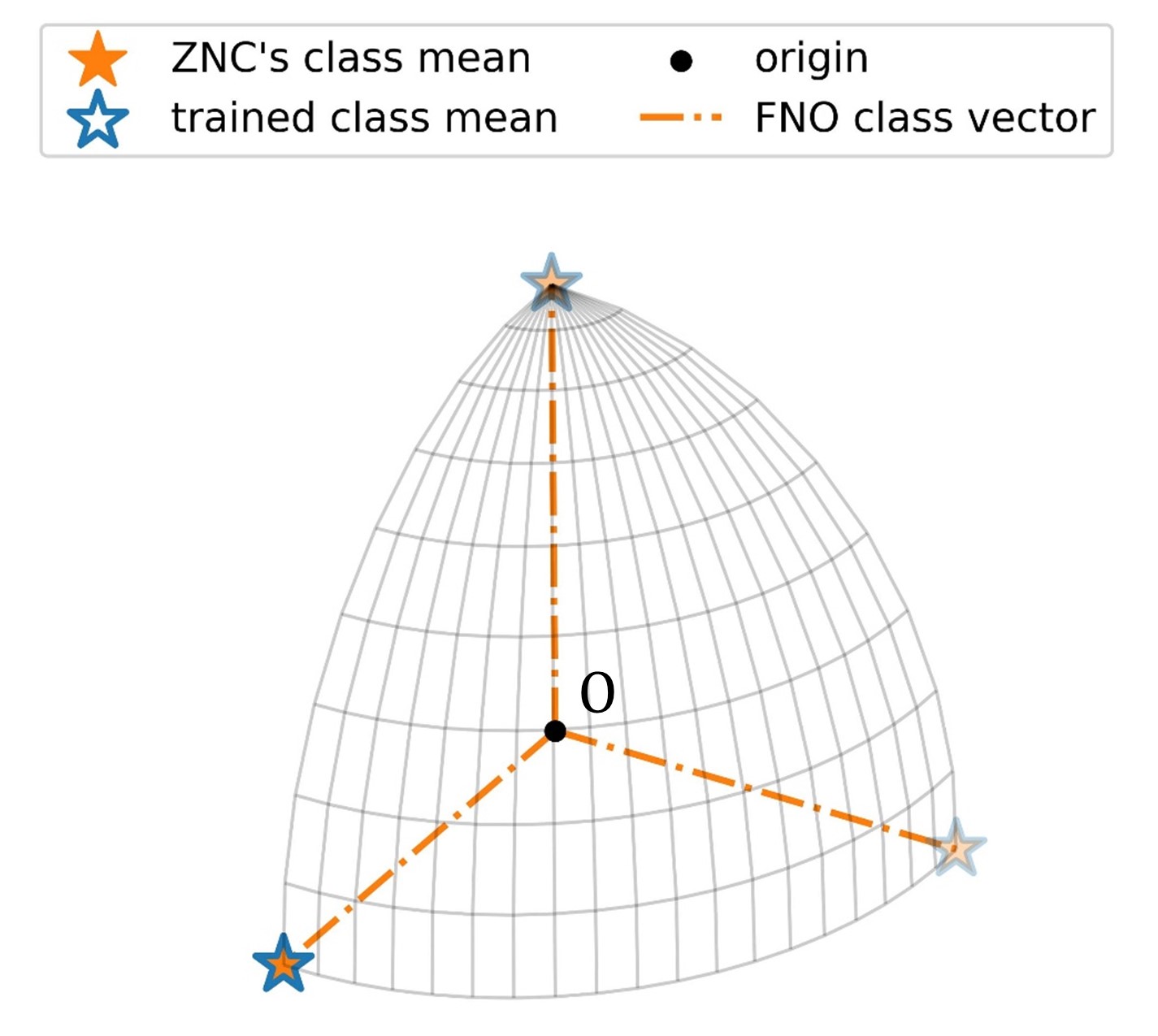
Fixed classifiers in neural networks for classification problems have demonstrated cost efficiency and even outperformed learnable classifiers in some popular benchmarks when incorporating orthogonality (Pernici et al., 2021a). Despite these advantages, prior research has yet to investigate the training dynamics of fixed classifiers on neural collapse. Ensuring this phenomenon is critical for obtaining global optimality in a layer-peeled model, potentially leading to enhanced performance in practice. However, the fixed classifiers cannot invoke neural collapse due to their geometric limitations. To overcome the limits, we analyze a zero-mean neural collapse considering the orthogonality in non-negative Euclidean space. Then, we propose a fixed non-negative orthogonal classifier that induces the optimal solution and maximizes the margin of an orthogonal layer-peeled model by satisfying the properties of zero-mean neural collapse. Building on this foundation, we exploit a feature dimension separation effect inherent in our classifier for further purposes; (1) enhances softmax masking by mitigating feature interference in continual learning and (2) tackles the limitations of mixup on the hypersphere in imbalanced learning. We conducted comprehensive experiments on various datasets and architectures and demonstrated significant performance improvements.
- Question: How the collapse between class means and class weight vectros occurs in a fixed classifier when its shape is not a simplex?
- Idea: When forcing non-negativity and orthogonality to the fixed classifier, zero-mean neural collapse occurs
- Dataset: Split-{MNIST,CIFAR10/100,TinyImageNet}, {CIFAR10/100,ImageNet,Places}-LT
- Method: Fixed Non-negative Orthogonal Classifier
- Keywords: neural collapse, orthogonal, fixed classifier, imbalanced, continual
Revisiting Softmax Masking: Stop Gradient for Enhancing Stability in Replay-based Continual Learning
Arxiv 2024
-
Abstract
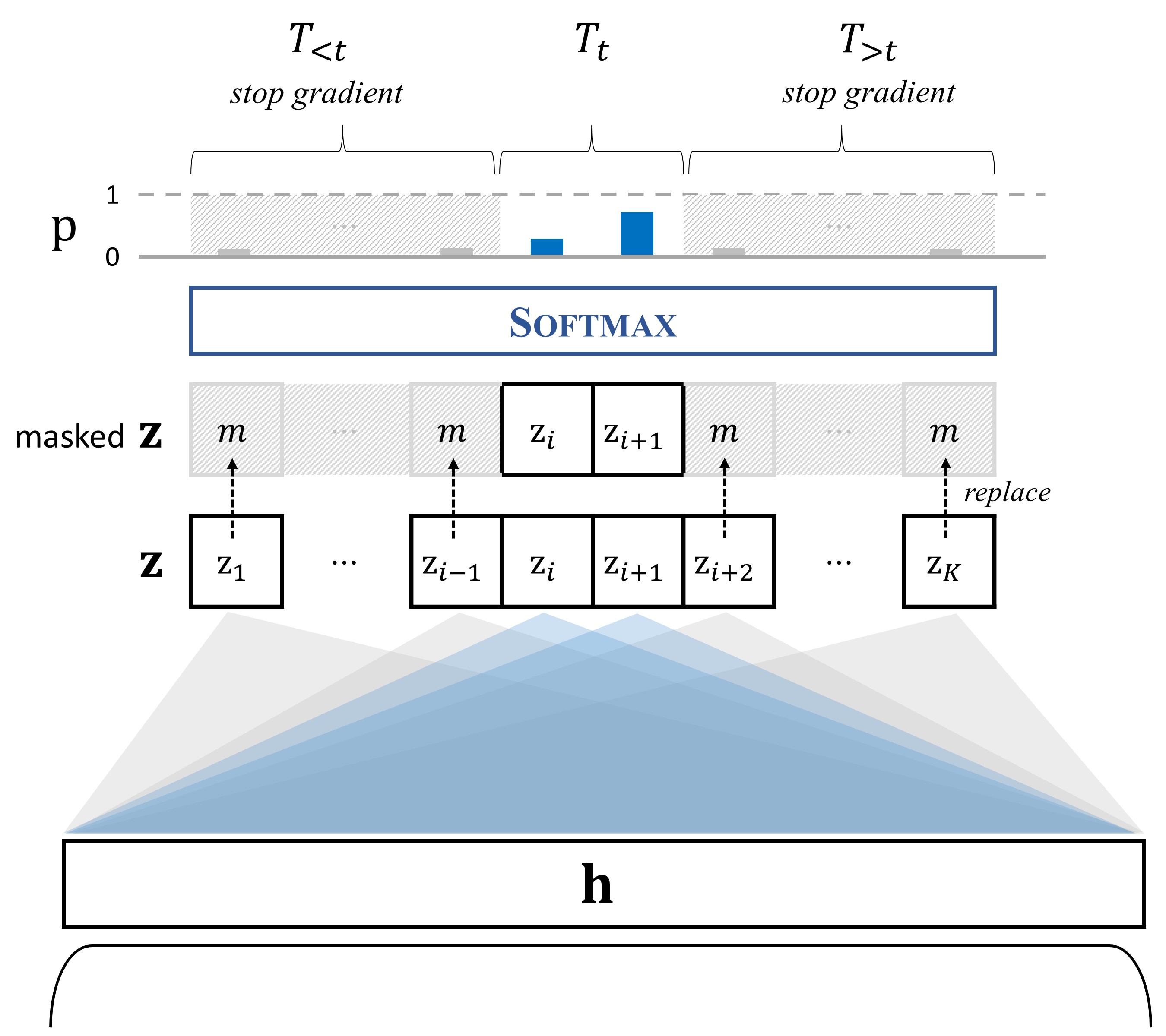
In replay-based methods for continual learning, replaying input samples in episodic memory has shown its effectiveness in alleviating catastrophic forgetting. However, the potential key factor of cross-entropy loss with softmax in causing catastrophic forgetting has been underexplored. In this paper, we analyze the effect of softmax and revisit softmax masking with negative infinity to shed light on its ability to mitigate catastrophic forgetting. Based on the analyses, it is found that negative infinity masked softmax is not always compatible with dark knowledge. To improve the compatibility, we propose a general masked softmax that controls the stability by adjusting the gradient scale to old and new classes. We demonstrate that utilizing our method on other replay-based methods results in better performance, primarily by enhancing model stability in continual learning benchmarks, even when the buffer size is set to an extremely small value.
- Question: How can we mitigate catastrophic forgetting caused by the push effect of cross-entropy loss with softmax in continual learning?
- Idea: Enhancing model stability by preventing the gradient flow from the target class to old and new classes for alleviating catastrophic forgetting
- Dataset: Split-{MNIST,CIFAR10/100,TinyImageNet}
- Method: General Masked Softmax
- Keywords: continual learning, softmax, mask, stop gradient
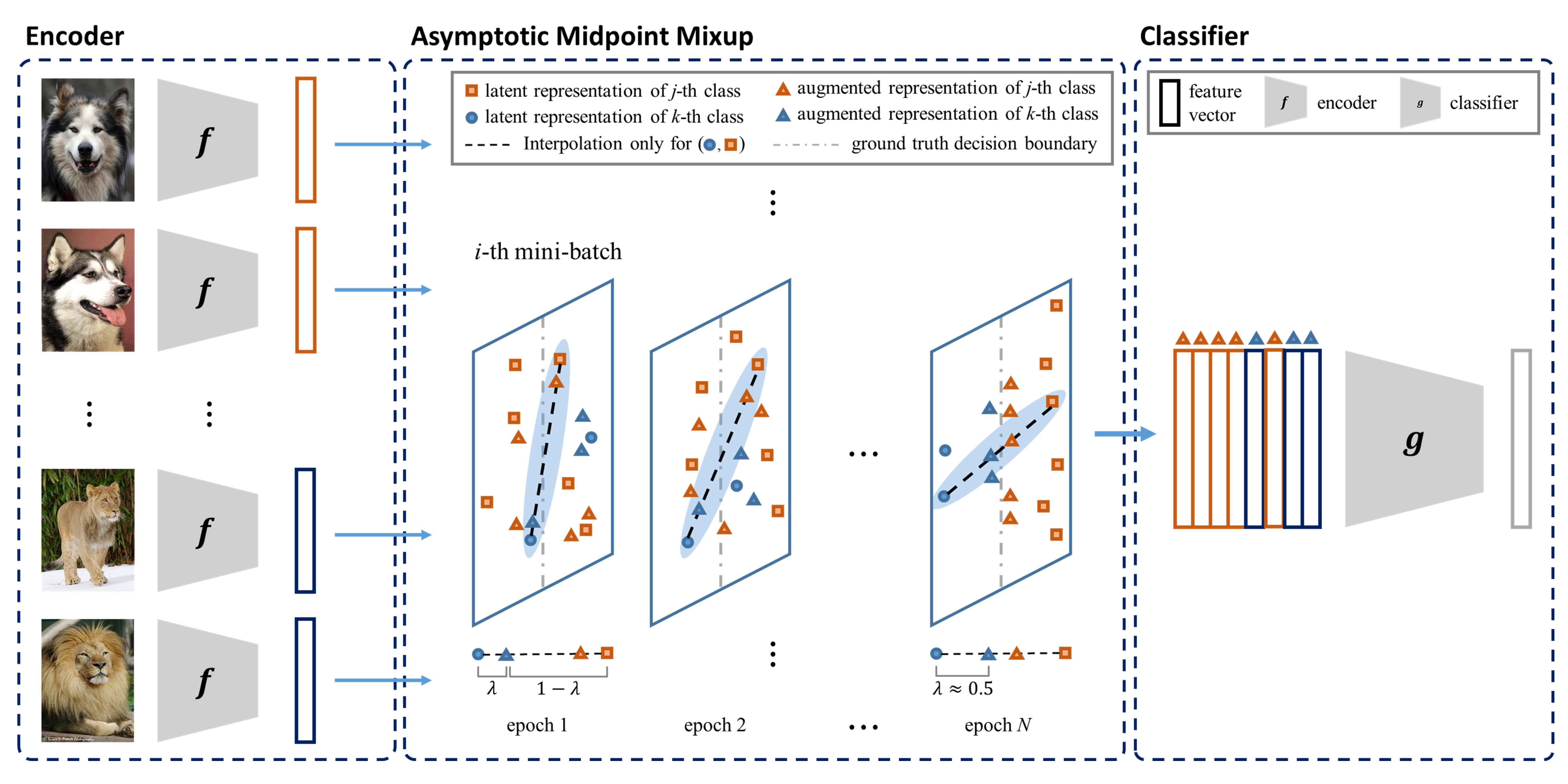
Asymptotic Midpoint Mixup for Margin Balancing and Moderate Broadening
Arxiv 2024
-
Abstract
In the feature space, the collapse between features invokes critical problems in representation learning by remaining the features undistinguished. Interpolation-based augmentation methods such as mixup have shown their effectiveness in relieving the collapse problem between different classes, called inter-class collapse. However, intra-class collapse raised in coarse-to-fine transfer learning has not been discussed in the augmentation approach. To address them, we propose a better feature augmentation method, asymptotic midpoint mixup. The method generates augmented features by interpolation but gradually moves them toward the midpoint of inter-class feature pairs. As a result, the method induces two effects; 1) balancing the margin for all classes and 2) only moderately broadening the margin until it holds maximal confidence. We empirically analyze the collapse effects by measuring alignment and uniformity with visualizing representations. Then, we validate the intra-class collapse effects in coarse-to-fine transfer learning and the inter-class collapse effects in imbalanced learning on long-tailed datasets. In both tasks, our method shows better performance than other augmentation methods.
- Question: How can we learn balanced margin in decision?
- Idea: Asymptotically mixup hidden vectors in the latent space
- Dataset: {CIFAR10/100,ImageNet,Places}-LT, {MNIST,CIFAR10/100}-CoarseToFine
- Method: Asymptotic Midpoint Mixup
- Keywords: augmentation, mixup, manifold mixup, imbalanced learning
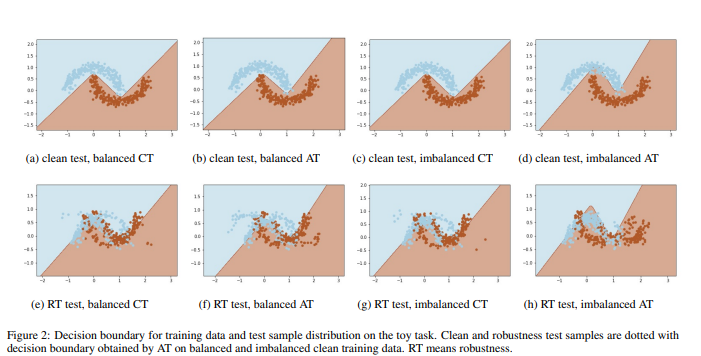
Enhancing Accuracy and Robustness through Adversarial Training in Class Incremental Continual Learning
arxiv
-
Abstract
In real life, adversarial attack to deep learning models is a fatal security issue. However, the issue has been rarely discussed in a widely used class-incremental continual learning (CICL). In this paper, we address problems of applying adversarial training to CICL, which is well-known defense method against adversarial attack. A well-known problem of CICL is class-imbalance that biases a model to the current task by a few samples of previous tasks. Meeting with the adversarial training, the imbalance causes another imbalance of attack trials over tasks. Lacking clean data of a minority class by the class-imbalance and increasing of attack trials from a majority class by the secondary imbalance, adversarial training distorts optimal decision boundaries. The distortion eventually decreases both accuracy and robustness than adversarial training. To exclude the effects, we propose a straightforward but significantly effective method, External Adversarial Training (EAT) which can be applied to methods using experience replay. This method conduct adversarial training to an auxiliary external model for the current task data at each time step, and applies generated adversarial examples to train the target model. We verify the effects on a toy problem and show significance on CICL benchmarks of image classification. We expect that the results will be used as the first baseline for robustness research of CICL.
- Question: How to preserve representations via adversarial training in continual learning.
- Idea: External adversarial sample generation
- Dataset: Cifar-10, Tiny image-net
- Method: Experience Replay, External Adversarial Training
- Keywords: Class-Incremental Continual Learning, Robustness, External Adversarial Training
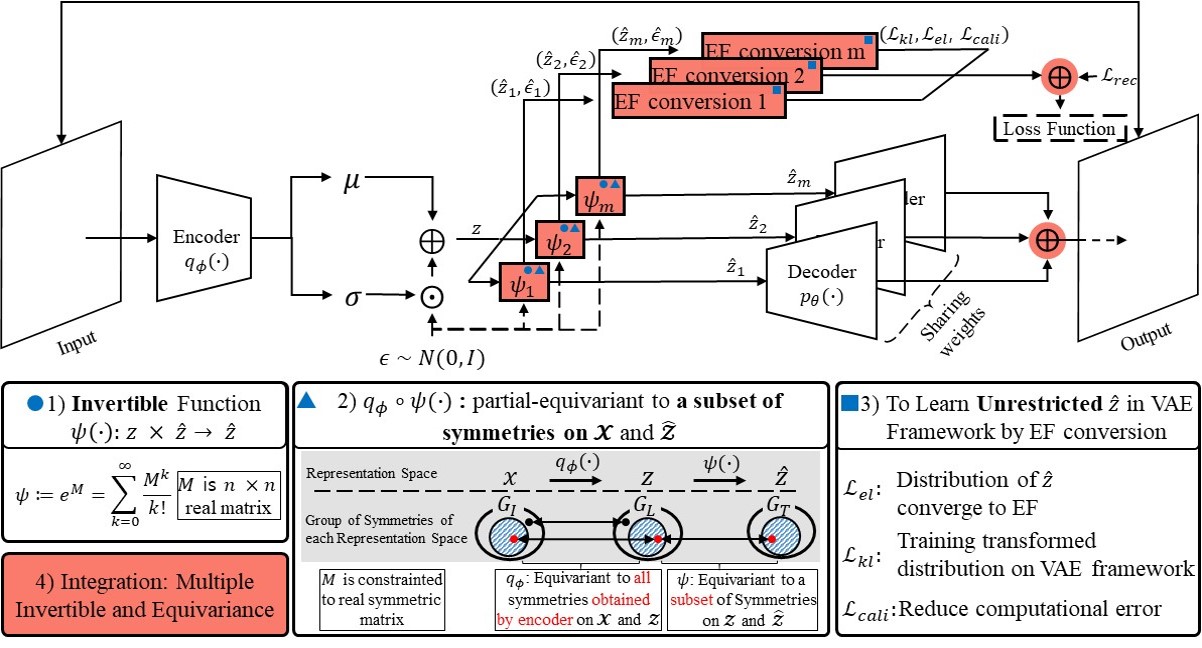
Multiple Invertible and Partial-Equivariant Function for Latent Vector Transformation to Enhance Disentanglement in VAEs
Submmitted Article (IEEE) "This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible" (2023. 05)
-
Abstract
Disentanglement learning is a core issue for understanding and re-using trained information in Variational AutoEncoder (VAE), and effective inductive bias has been reported as a key factor. However, the actual implementation of such bias is still vague. In this paper, we propose a novel method, called Multiple Invertible and partial-equivariant transformation (MIPE-transformation), to inject inductive bias by 1) guaranteeing the invertibility of latent-to-latent vector transformation while preserving a certain portion of equivariance of input-to-latent vector transformation, called Invertible and partial-equivariant transformation (IPE-transformation), 2) extending the form of prior and posterior in VAE frameworks to an unrestricted form through a learnable conversion to an approximated exponential family, called Exponential Family conversion (EF-conversion), and 3) integrating multiple units of IPE-transformation and EF-conversion, and their training. In experiments on 3D Cars, 3D Shapes, and dSprites datasets, MIPE-transformation improves the disentanglement performance of state-of-the-art VAEs.
- Question: How to inject inductive bias for learning unsupervised disentangled representations.
- Idea: Invertible and Partial-Equivariant function for disentanglement learning.
- Dataset: 3D Cars, dSprites, 3D Shapes
- Method: Multiple Invertible and Partial-Equivariant Transformation (MIPET)
- Keywords: Invertible, Partial-Equivariant, Disentanglement learning, Variational Auto-Encoder (VAE)
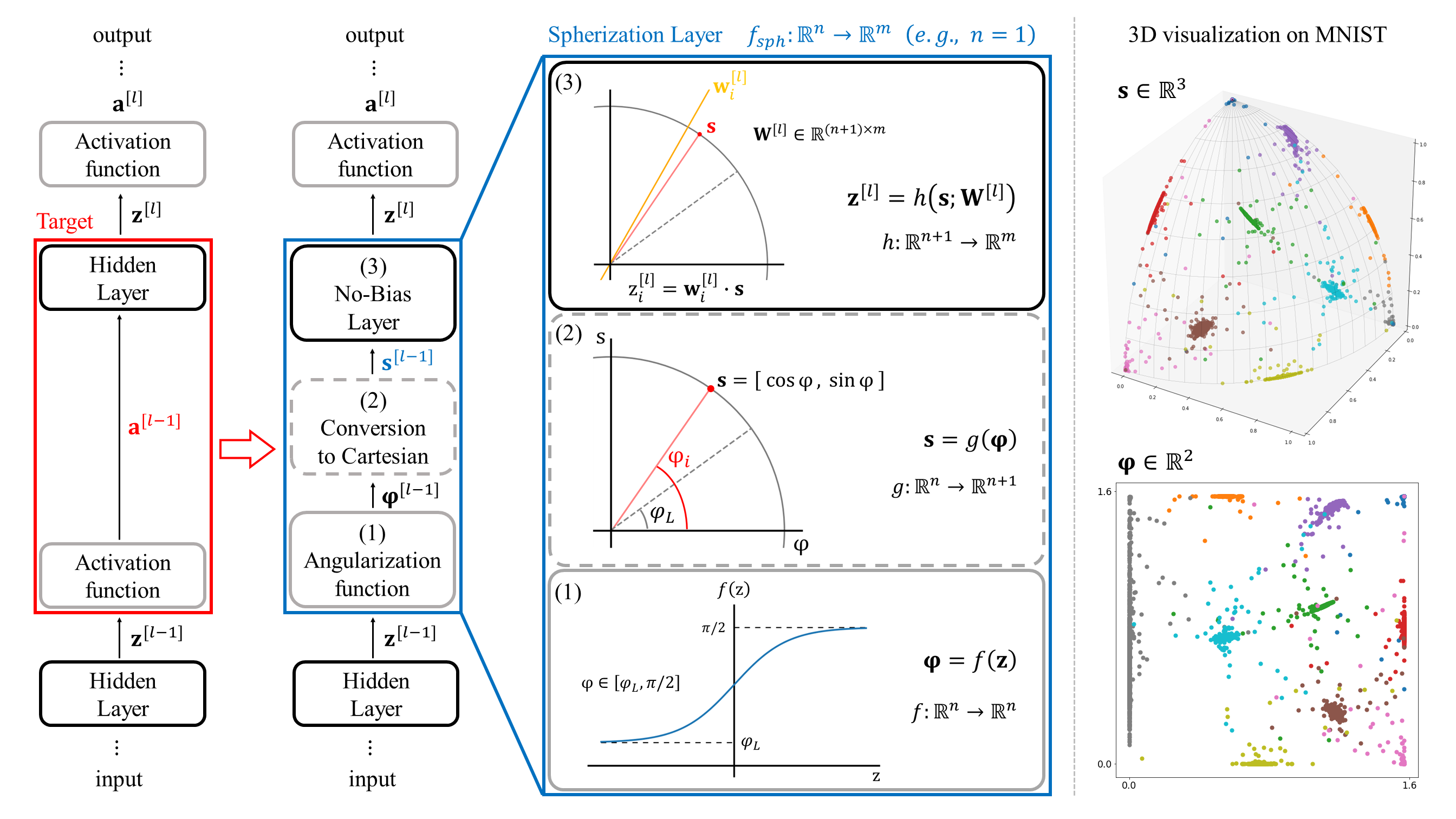
Spherization Layer: Representation Using Only Angles
36th Conference on Neural Information Processing Systems (NeurIPS 2022)
-
Abstract
In neural network literature, angular similarity between feature vectors is frequently used for interpreting or re-using learned representations. However, the inner product in neural networks partially disperses information over the scales and angles of the involved input vectors and weight vectors. Therefore, when using only angular similarity on representations trained with the inner product, information loss occurs in downstream methods, which limits their performance. In this paper, we proposed the spherization layer to represent all information on angular similarity. The layer 1) maps the pre-activations of input vectors into the specific range of angles, 2) converts the angular coordinates of the vectors to Cartesian coordinates with an additional dimension, and 3) trains decision boundaries from hyperplanes, without bias parameters, passing through the origin. This approach guarantees that representation learning always occurs on the hyperspherical surface without the loss of any information unlike other projection-based methods. Furthermore, this method can be applied to any network by replacing an existing layer. We validate the functional correctness of the proposed method in a toy task, retention ability in well-known image classification tasks, and effectiveness in word analogy test and few-shot learning. Code is publicly available at https://github.com/GIST-IRR/spherization_layer
- Question: How about learning representations using only the angles and using them on angular similarity?
- Idea: Learn feature representations by using only angles.
- Dataset: MNIST, Fashion-MNIST, CIFAR10/100, WikiText, Mini-ImageNet
- Method: Spherization Layer
- Keywords: representation learning, spherization, angular similarity
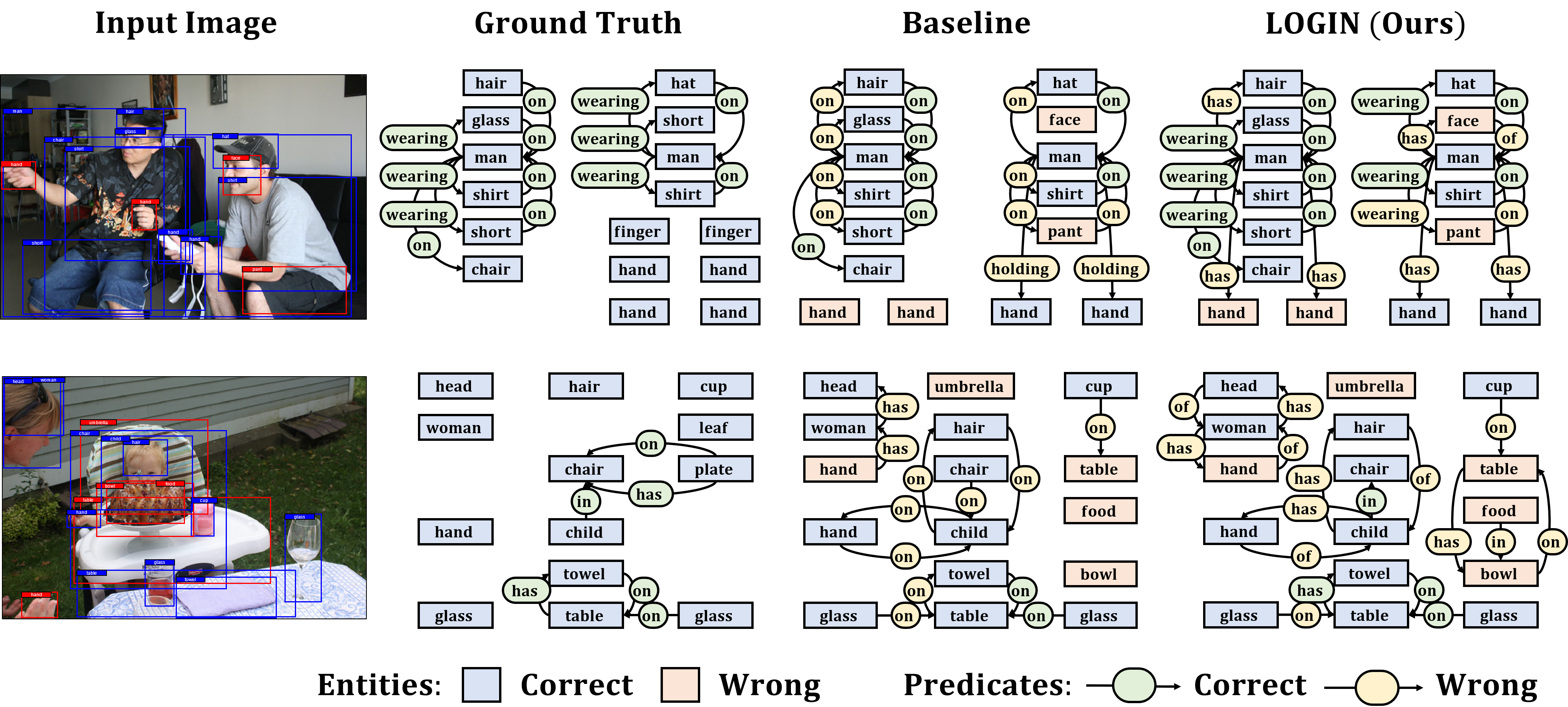
Tackling the Challenges in Scene Graph Generation with Local-to-Global Interactions
IEEE Transactions on Neural Networks and Learning Systems (TNNLS 2022)
-
Abstract
In this work, we seek new insights into the underlying challenges of the Scene Graph Generation (SGG) task. Quantitative and qualitative analysis of the Visual Genome dataset implies 1) Ambiguity - even if inter-object relationship contains the same object (or predicate), they may not be visually or semantically similar, 2) Asymmetry - despite the nature of the relationship that embodied the direction, it was not well addressed in previous studies, and 3) Higher-order contexts - leveraging the identities of certain graph elements can help to generate accurate scene graphs. Motivated by the analysis, we design a novel SGG framework, Local-to-Global Interaction Networks (LOGIN). Locally, interactions extract the essence between three instances - subject, object, and background - while baking direction awareness into the network by constraining the input order. Globally, interactions encode the contexts between every graph components -- nodes and edges. Also we introduce Attract & Repel loss which finely adjusts predicate embeddings. Our framework enables predicting the scene graph in a local-to-global manner by design, leveraging the possible complementariness. To quantify how much LOGIN is aware of relational direction, we propose a new diagnostic task called Bidirectional Relationship Classification (BRC). We see that LOGIN can successfully distinguish relational direction than existing methods (in BRC task) while showing state-of-the-art results on the Visual Genome benchmark (in SGG task).
- Question: Which of the issues that reflect the nature of the data itself has not been addressed in depth in previous studies?
- Idea: The characteristics shared by target issues are solved simultaneously using a bottom-up approach.
- Dataset: Visual Genome
- Method: Local-to-Global Interaction Network (LOGIN)
- Keywords: Scene Graph Generation (SGG), Scene Understanding, Relationship Detection, Bidirectional Relationship Classification
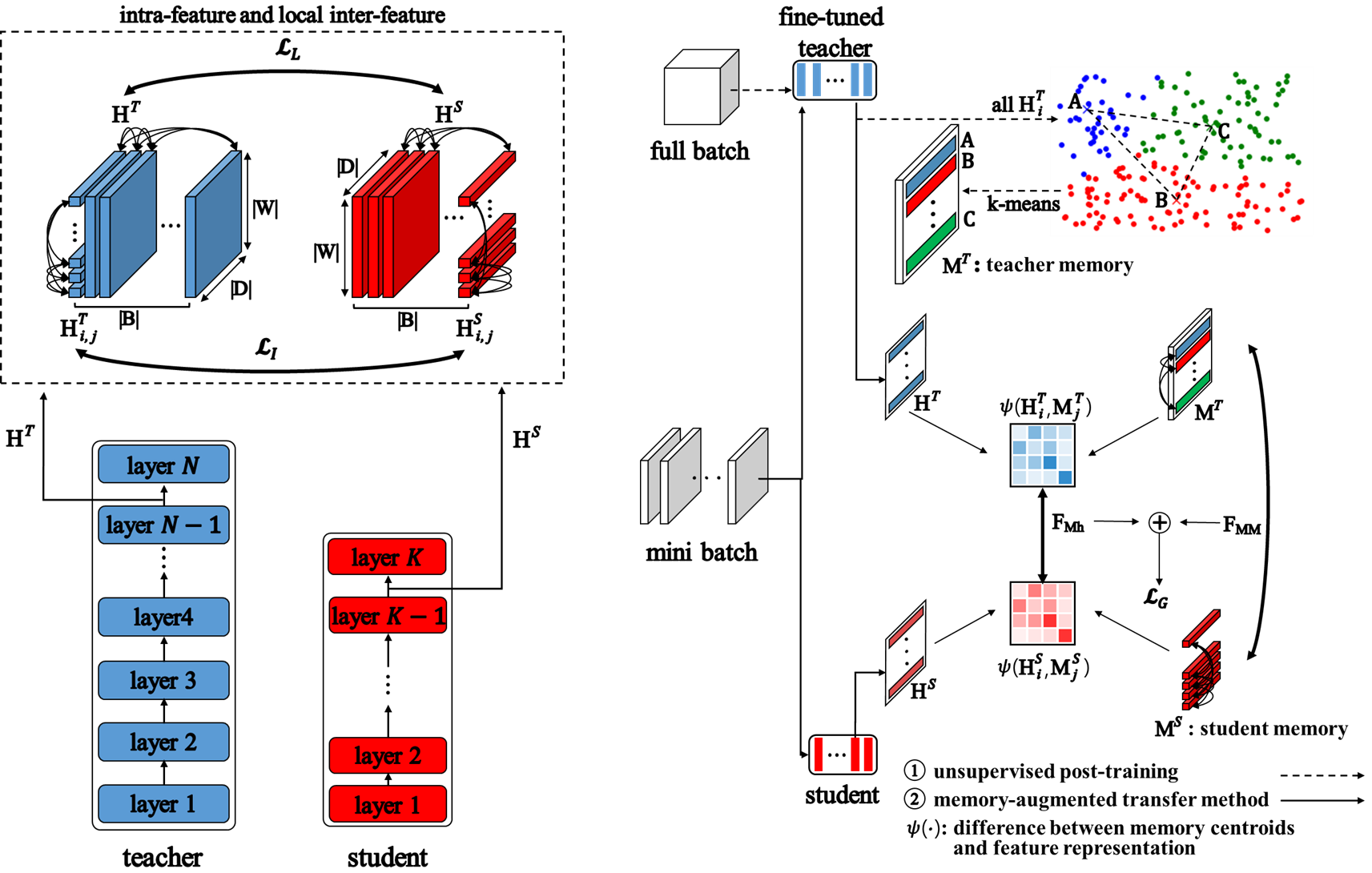
Feature Structure Distillation with Centered Kernel Alignment in BERT Transferring
ELSEVIER Expert Systems with Applications (ESWA 2023)
-
Abstract
Knowledge distillation is an approach to transfer information on representations from a teacher to a student by reducing their difference. A challenge of this approach is to reduce the flexibility of the student's representations inducing inaccurate learning of the teacher's knowledge. To resolve it in transferring, we investigate distillation of structures of representations specified to three types: intra-feature, local inter-feature, global inter-feature structures, instead representations. To transfer them, we introduce feature structure distillation methods based on the Centered Kernel Alignment (CKA), which assigns a consistent value to similar feature structures and reveals more informative relations. We implement intra-feature structure with the relation between tokens in single sentence, and inter feature structure with the relation between sentences in mini-batch. In particular, a memory-augmented transfer method with clustering is implemented for the global structures. Then we utilize the CKA metric to transfer the teacher's structure to student's through layer-wise distillation. The methods are empirically analyzed on the nine tasks for language understanding of the GLUE dataset with Bidirectional Encoder Representations from Transformers (BERT), which is a representative neural language model. In the results, the proposed methods effectively transfer the three types of structures and improve performance compared to state-of-the-art distillation methods. Indeed, the code for the methods is available at https://github.com/maroo-sky/FSD.
- Question: How to transfer the feature structure from teacher to student model?
- Idea: Transfer relation of teacher's knowledge to student.
- Dataset: GLUE
- Method: Feature Structure Distillation (FSD)
- Keywords: Knowledge Distillation, Centered Kernel Alignment, Feature Sturcture, BERT, Natural Language Processing
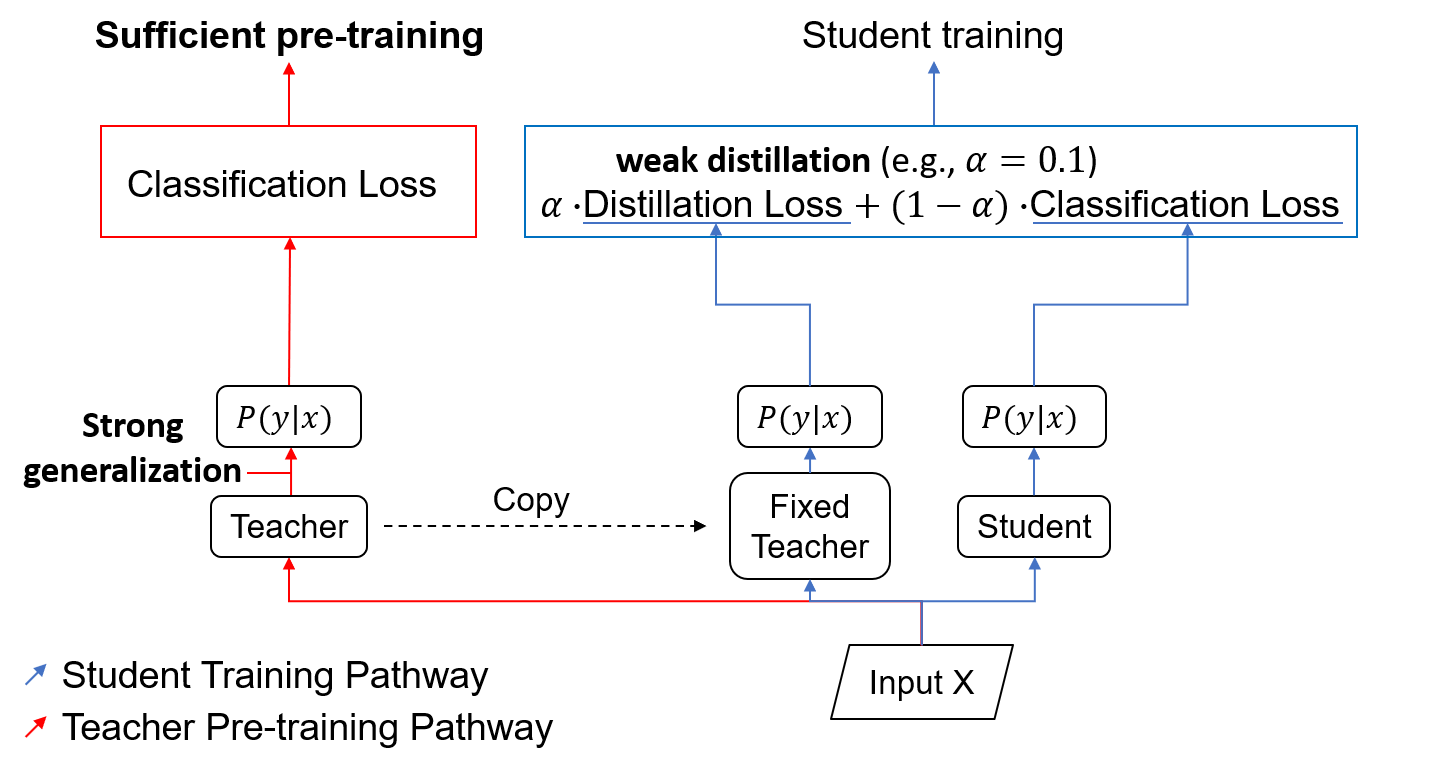
Learning from Matured Dumb Teacher for Fine Generalization
Arxiv 2021
-
Abstract
The flexibility of decision boundaries in neural networks that are unguided by training data is a well-known problem typically resolved with generalization methods. A surprising result from recent knowledge distillation (KD) literature is that random, untrained, and equally structured teacher networks can also vastly improve generalization performance. It raises the possibility of existence of undiscovered assumptions useful for generalization on an uncertain region. In this paper, we shed light on the assumptions by analyzing decision boundaries and confidence distributions of both simple and KD-based generalization methods. Assuming that a decision boundary exists to represent the most general tendency of distinction on an input sample space (i.e., the simplest hypothesis), we show the various limitations of methods when using the hypothesis. To resolve these limitations, we propose matured dumb teacher based KD, conservatively transferring the hypothesis for generalization of the student without massive destruction of trained information. In practical experiments on feed-forward and convolution neural networks for image classification tasks on MNIST, CIFAR-10, and CIFAR-100 datasets, the proposed method shows stable improvement to the best test performance in the grid search of hyperparameters. The analysis and results imply that the proposed method can provide finer generalization than existing methods.
- Idea: Using the simplest hypothese to generalize the model only with given training data.
- Dataset: MNIST, CIFAR-10, CIFAR-100
- Method: matured Dumb Teacher based Knowledge Distillation (mDT-KD)
- Keywords: Generalization, Self-knowledge distillation, Neural networks, Occam’s Razor, Confidence distribution, Decision boundary
What and When to Look?: Temporal Span Proposal Network for Video Visual Relation Detection
Arxiv 2021

-
Abstract
Identifying relations between objects is central to understanding the scene. While several works have been proposed for relation modeling in the image domain, there have been many constraints in the video domain due to challenging dynamics of spatio-temporal interactions (e.g., Between which objects are there an interaction? When do relations occur and end?). To date, two representative methods have been proposed to tackle Video Visual Relation Detection (VidVRD) - segment-based and window-based. We first point out the limitations these two methods have and propose Temporal Span Proposal Network (TSPN), a novel method with two advantages in terms of efficiency and effectiveness. 1) TSPN tells what to look - it sparsifies relation search space by scoring relationness (i.e., confidence score for the existence of a relation between pair of objects) of object pair. 2) TSPN tells when to look - it leverages the full video context to simultaneously predict the temporal span and categories of the entire relations. TSPN demonstrates its effectiveness by achieving new state-of-the-art by a significant margin on two VidVRD benchmarks (ImageNet-VidVDR and VidOR) while also showing lower time complexity than existing methods - in particular, twice as efficient as a popular segment-based approach.
- Question: How can we extract long-term relation better from a video?
- Idea: Directly propose a temporal span over object trajectories.
- Dataset: ImageNet-VidVRD, VidOR
- Method: Temporal Span Proposal Network (TSPN)
- Keywords: Video Visual Relation Detection (VidVRD), Spatio-temporal Video Understanding, Temporal Relation Localization
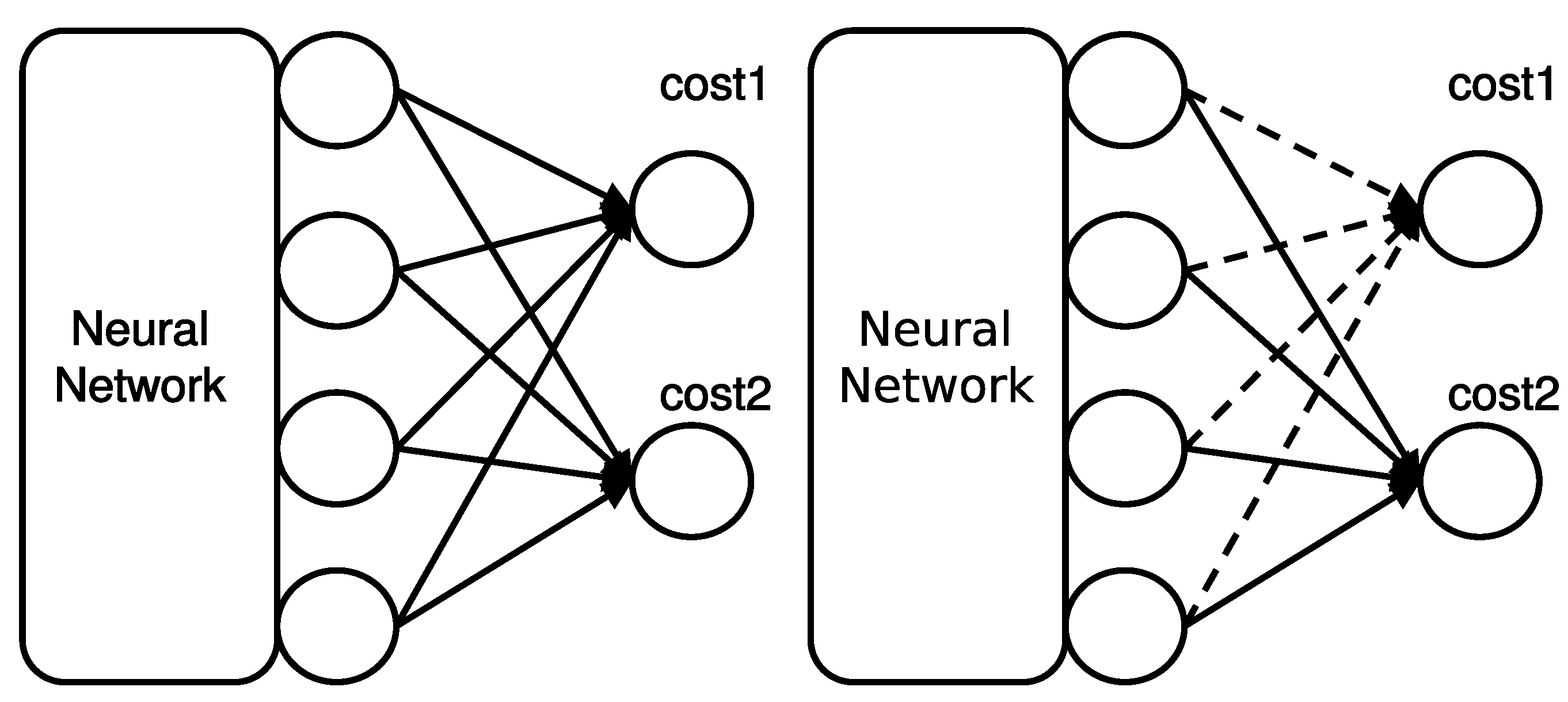
Revisiting Dropout: Escaping Pressure for Training Neural Networks with Multiple Costs
Electronics 2021
-
Abstract
A common approach to jointly learn multiple tasks with a shared structure is to optimize the model with a combined landscape of multiple sub-costs. However, gradients derived from each sub-cost often conflicts in cost plateaus, resulting in a subpar optimum. In this work, we shed light on such gradient conflict challenges and suggest a solution named Cost-Out, which randomly drops the sub-costs for each iteration. We provide the theoretical and empirical evidence of the existence of escaping pressure induced by the Cost-Out mechanism. While simple, the empirical results indicate that the proposed method can enhance the performance of multi-task learning problems, including two-digit image classification sampled from MNIST dataset and machine translation tasks for English from and to French, Spanish, and German WMT14 datasets.
- Question: What leads to sub-par optimum in the multi-task learning environment?
- Idea: Resolve gradient conflicts among multiple tasks via drop-out-like mechanism.
- Dataset: MNIST, WMT14
- Method: Cost-Out
- Keywords: Multitask Learning, Gradient Conflict, Escaping Pressure, Dropout